河套 IT TALK——TALK 12:编程的技术|艺术|术术 下篇:对着代码解读编程的哲学
前期回顾
前面两篇里,骨灰级程序员梁峻墅给大家介绍了他的心路历程,他谈了程序员文化和武林文化的理解,将编程与孙子兵法对照,阐释编程的艺术性表达以及哲学思考。本篇将不再务虚,而是直接上代码,让梁老师带着你解读牛逼代码的高明之处。

一段黑客的代码
务虚的事都讲完了,现在得真的要讲讲务实的事了。前面讲的那些是武功秘籍的目录,而真正的武功秘籍在代码里。实践出真知,只有虚实结合,才能感同身受。
我找了一段Zero-Day(编者注:下文简称0day)组织几乎每个程序都要用到的一段代码作为示例。

0day,用过盗版软件的朋友应该都很熟悉,它是全球最牛B的盗版组织,里面高手如云,都是Richard Stallman的追随者。任何一个被他们盯上的大厂软件,只要敢早上发布,中午的发布会招待宴还没吃完,破解版就已经在各大盗版网站上可以下载了,平均破解时间就是两三个小时,承诺破解时间不超过24小时,所以叫0day,当天解决,童叟无欺。我们就来看看这些全球顶尖黑客是怎么写代码的。
我找的这段代码的功能很简单,就是一个基于文件的记录日志类,其C++版本加上头文件,总代码行数不超过200行,而核心代码不到100行,但就在这方寸之间,隐藏着十一个战术思想,三个战略思想,还有三个核弹级思想。就是个日志文件功能,如果是你设计,能有什么想法?而往往是简单中蕴含的伟大,才能更加让人震撼。现在咱们就按图索骥,开始一段与顶尖高手同行的代码探险之旅。
这段代码是个标准的C++类,为方便演示,我使用的是其Windows平台的版本,此类可以在所有Visual Studio的C++应用中使用,就两个文件:LogFile.h和LogFile.cpp。
可以先总览一下:
LogFile.h
// Log.h: interface for the CLog class.
//
//////////////////////////////////////////////////////////////////////
#if !defined(AFX_LOG_H__512AFEC0_D4E8_47F0_AB0C_4E29DAB9A9FC__INCLUDED_)
#define AFX_LOG_H__512AFEC0_D4E8_47F0_AB0C_4E29DAB9A9FC__INCLUDED_
#if _MSC_VER > 1000
#pragma once
#endif // _MSC_VER > 1000
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <io.h>
#include <tchar.h>
#include <Windows.h>
#define MAX_LENGTH_CONTENT_PER_LINE 1024
class CLogFile {
public:
CLogFile(LPCTSTR pszPathName4User = _T(""));
virtual ~CLogFile();
bool Record(LPCTSTR pszFormat, ...);
bool SetPathName4Host(LPCTSTR pszPathName4Host);
bool SetPathName4User(LPCTSTR pszPathName4User);
bool SetFileName4Host(LPCTSTR pszFileName4Host);
bool SetFileName4User(LPCTSTR szFileName4User);
bool SetHeader(LPCTSTR szHeader);
LPCTSTR GetPathName4Host();
LPCTSTR GetPathName4User();
LPCTSTR GetFileName4Host();
LPCTSTR GetFileName4User();
LPCTSTR GetPathName();
LPCTSTR GetFileNameFullPath();
protected:
SYSTEMTIME m_tSystemTime;
TCHAR m_szPathName4Host[MAX_PATH + 1];
TCHAR m_szPathName4User[MAX_PATH + 1];
TCHAR m_szFileName4Host[MAX_PATH + 1];
TCHAR m_szFileName4User[MAX_PATH + 1];
TCHAR m_szPathName[MAX_PATH + 1];
TCHAR m_szFileNameFullPath[MAX_PATH + 1];
TCHAR m_szHeader[MAX_LENGTH_CONTENT_PER_LINE + 1];
TCHAR m_szLine[MAX_LENGTH_CONTENT_PER_LINE + 1];
bool IsPathOrFileExist(LPCTSTR pszPathOrFileName);
bool BuildFilePath();
bool BuildPathAndFilePath();
};
#endif // !defined(AFX_LOG_H__512AFEC0_D4E8_47F0_AB0C_4E29DAB9A9FC__INCLUDED_)LogFile.cpp
// Log.cpp: implementation of the CLog class.
//
//////////////////////////////////////////////////////////////////////
#include "LogFile.h"
#define ZERO_MEMORY(p) memset(p, 0, sizeof(p))
CLogFile::CLogFile(LPCTSTR pszPathName4User) {
ZERO_MEMORY(m_szPathName4Host);
ZERO_MEMORY(m_szPathName4User);
ZERO_MEMORY(m_szFileName4Host);
ZERO_MEMORY(m_szFileName4User);
ZERO_MEMORY(m_szPathName);
ZERO_MEMORY(m_szFileNameFullPath);
ZERO_MEMORY(m_szLine);
ZERO_MEMORY(m_szHeader);
_tcscpy_s(m_szHeader, MAX_LENGTH_CONTENT_PER_LINE, _T("F0\tF1\tF2\tF3\tF4\tF5\tF6\tF7\tF8\tF9\tF10\tF11\tF12\tF13\tF14\tF15"));
::GetModuleFileName(NULL, m_szFileNameFullPath, MAX_PATH);
_tsplitpath(m_szFileNameFullPath, m_szPathName4Host, m_szPathName, m_szFileName4Host, NULL);
_tcscat_s(m_szPathName4Host, MAX_PATH, m_szPathName);
if (pszPathName4User) {
if (*pszPathName4User) {
_tcscpy_s(m_szPathName4User, MAX_PATH, pszPathName4User);
}
else {
*m_szPathName4User = _T('.');
_tcscat_s(m_szPathName4User, MAX_PATH, m_szFileName4Host);
}
}
BuildPathAndFilePath();
}
CLogFile::~CLogFile() {
}
bool CLogFile::BuildFilePath() {
GetLocalTime(&m_tSystemTime);
int iReturn = _sntprintf(m_szFileNameFullPath, MAX_PATH, _T("%s\\%s.%s.%04d%02d%02d.%p.txt"),
m_szPathName, m_szFileName4Host, m_szFileName4User,
m_tSystemTime.wYear, m_tSystemTime.wMonth, m_tSystemTime.wDay, this);
return 0 < iReturn;
}
bool CLogFile::BuildPathAndFilePath() {
bool bReturn = 0 < _sntprintf(m_szPathName, MAX_PATH, _T("%s\\%s"), m_szPathName4Host, m_szPathName4User);
if (bReturn) {
bReturn = BuildFilePath();
}
return bReturn;
}
bool CLogFile::Record(LPCTSTR pszFormat, ...) {
int iReturn = 0;
FILE* pFile = NULL;
do {
if (!IsPathOrFileExist(m_szPathName)) {
break;
}
if (!BuildFilePath()) {
break;
}
bool bIsNew = !IsPathOrFileExist(m_szFileNameFullPath);
pFile = _tfopen(m_szFileNameFullPath, _T("a"));
if (!pFile) {
break;
}
if (bIsNew) {
iReturn = _ftprintf(pFile, _T("Time\tUser\t%s\n"), m_szHeader);
if (0 >= iReturn) {
break;
}
}
va_list vlArgs;
va_start(vlArgs, pszFormat);
iReturn = _vsntprintf(m_szLine, MAX_LENGTH_CONTENT_PER_LINE, pszFormat, vlArgs);
va_end(vlArgs);
if (0 > iReturn) {
break;
}
iReturn = _ftprintf(pFile, _T("%02d:%02d:%02d.%03d\t%s\t%s\n"), m_tSystemTime.wHour,
m_tSystemTime.wMinute, m_tSystemTime.wSecond, m_tSystemTime.wMilliseconds,
m_szFileName4User, m_szLine);
} while (false);
if (pFile) {
fclose(pFile);
}
return 0 < iReturn;
}
bool CLogFile::IsPathOrFileExist(LPCTSTR pszPathOrFileName) {
return (0 == _taccess(pszPathOrFileName, 0));
}
bool CLogFile::SetPathName4Host(LPCTSTR pszPathName4Host) {
_tcsncpy(m_szPathName4Host, pszPathName4Host, MAX_PATH);
return BuildPathAndFilePath();
}
bool CLogFile::SetPathName4User(LPCTSTR pszPathName4User) {
_tcsncpy(m_szPathName4User, pszPathName4User, MAX_PATH);
return BuildPathAndFilePath();
}
bool CLogFile::SetFileName4Host(LPCTSTR pszFileName4Host) {
_tcsncpy(m_szFileName4Host, pszFileName4Host, MAX_PATH);
return BuildFilePath();
}
bool CLogFile::SetFileName4User(LPCTSTR szFileName4User) {
_tcsncpy(m_szFileName4User, szFileName4User, MAX_PATH);
return BuildFilePath();
}
bool CLogFile::SetHeader(LPCTSTR szHeader) {
_tcsncpy(m_szHeader, szHeader, MAX_PATH);
return true;
}
LPCTSTR CLogFile::GetPathName4Host() {
return m_szPathName4Host;
}
LPCTSTR CLogFile::GetPathName4User() {
return m_szPathName4User;
}
LPCTSTR CLogFile::GetFileName4Host() {
return m_szFileName4Host;
}
LPCTSTR CLogFile::GetFileName4User() {
return m_szFileName4User;
}
LPCTSTR CLogFile::GetPathName() {
return m_szPathName;
}
LPCTSTR CLogFile::GetFileNameFullPath() {
return m_szFileNameFullPath;
}战术思想
先从战术思想谈起,有十一个,容我逐一道来。
战术思想一:全名命名规则
代码的第一眼感觉,没有注释!这帮高手果然很清高啊,他们不会帮助你看懂,因为这个世界上总有人不配看懂。只能沉下心来,自力更生了。再仔细看代码,会发现代码中的变量名、方法名都很长。第一个战术级思想浮出水面:全名命名规则。命名使用单词全名,而很多程序员喜欢使用缩写,而缩写并不一定能与所有人达成共识,导致命名的意义大打折扣。良好的命名可以代替注释,且效率更高。微软的函数命名平均长度是13个字母,而0day代码中的命名平均长度是16.8个字母,超过微软水准将近30%。可以说,命名平均长度能够作为代码段位的参考之一。
战术思想二:前缀命名规则
再仔细看每一个命名,第二个战术级思想浮出水面:前缀命名规则。所有的变量名都有类型前缀,如字符串变量的前缀是“sz”,字符串指针变量的前缀是“psz” ,整型(int)变量的前缀是“i” ,布尔型(bool)变量的前缀是“b”,这些类型前缀虽然使用了缩写,但这些缩写都是C/C++程序员所共识的。还有,所有的类成员级变量在类型前缀前再加上“m_”前缀指示作用域,m是member的缩写,其实还有一个“g_”前缀代表全局作用域,但全局变量只有在C代码中很常见,而在C++代码中几乎从不使用。
战术思想三:名词前置命名规则
再再仔细看每一个命名,第三个战术级思想浮出水面:名词前置命名规则。例如类成员字符串变量“宿主路径名”命名为m_szPathName4Host,“用户路径名”命名为m_szPathName4User,如果按人类正常思维应该是m_szHostPathName和m_szUserPathName才对,但他们却名词前置,形容词动词后置。其目的是为了给相关命名进行分类,最早是为了能在代码统计工具的报告中,能把相关命名在α排序中排在一起,以便进行代码分析;而在后来的现代IDE的代码编辑器中,都有自动完成功能,根据输入的部分字母自动提示可能的输入,按名词前置命名规则,提示内容将把相关命名排在一起,便于程序员选择。如键入“m_szP”,将提示出m_szPathName4Host和m_szPathName4User,方便程序员在使用相关变量或方法时提高效率。
战术思想四:介词缩写命名规则
在上面提到的命名中,都有一个阿拉伯数字4,这是什么鬼?第四个战术级思想浮出水面:介词缩写命名规则。用4的英文谐音代替介词“for”,原命名应为m_szPathNameForHost,介词作为前置命名分类与后置形容词、动词的分界线被大量使用,为节约键击次数而在组织内约定的缩写。类似还有2,谐音英文的“to”,因为在程序中各种转换也非常多,如BinToHex(二进制转十六进制),可以缩写为Bin2Hex。这可以理解为长命名思想与少键击思想的辩证统一。
战术思想五:对称命名规则
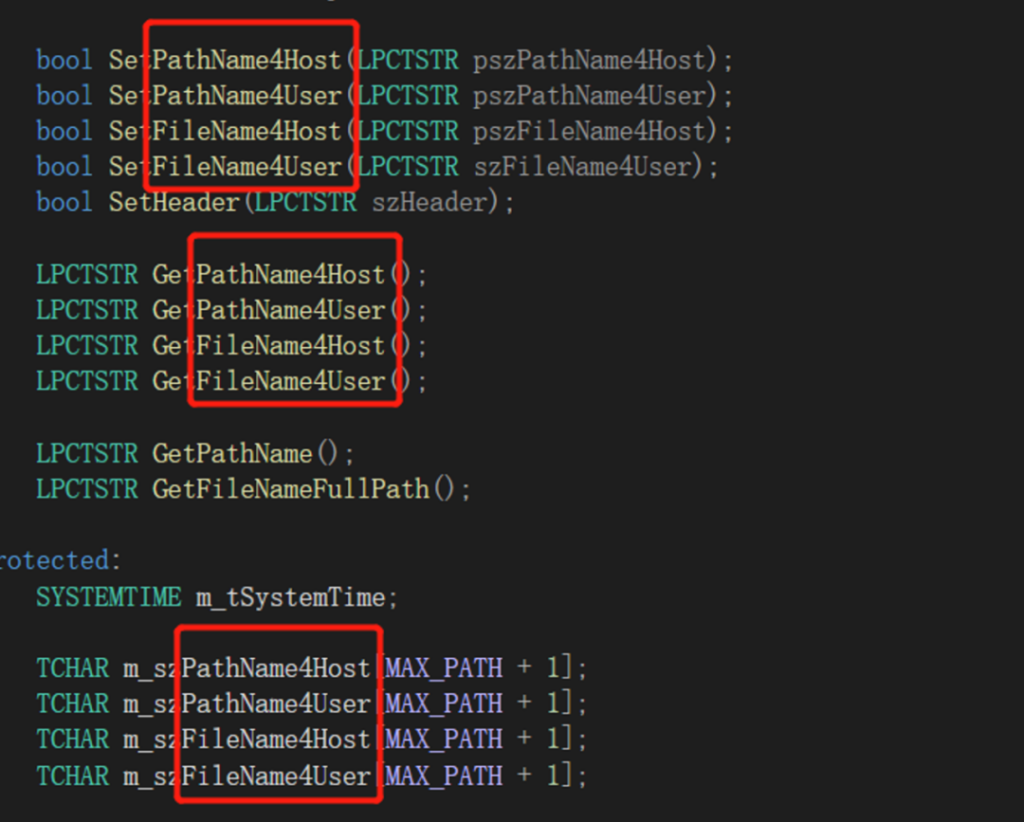
看上面的成员变量和对应的设置方法名和获取方法名,第五个战术级思想浮出水面:对称命名规则。如此整齐划一的命名,不但能帮助阅读者在没有注释的情况下快速理解各方法的意图,还能让使用者无需翻看源码就能准确调用。
大家看看,一个小小的命名,已经是杀机四伏,下足了功夫。十一个战术思想接近一半,都是在谈命名。就是因为命名是代码的基石,它是多米诺骨牌效应里的第一块骨牌,每块砖不做好,将会影响整个大厦的安危。这些命名规则的终极目标都是为了用空间换时间。在你的每一次键击中,每个思想可能只为你节约了0.1秒,但经不住长年累月的积累,你的有效编程时间就是比别人多,还没开始比赛,你就已经胜过了。
战术思想六:使用制表符缩进
代码中还有一个不易察觉的细节,其代码缩进使用的是制表符(TAB键),第六个战术级思想浮出水面:使用制表符缩进。关于缩进使用制表符还是空格,业界一直争论不断,且没什么定论,主要原因就是觉得这是个小问题,无伤大雅,大家随意,开心就好。但这些顶尖高手只用制表符,原因很暖心,仅仅是为了尊重同行!制表符最早出现是为了控制打印机在打印时的左边距,当时定义为8个空格,可视化编程出现后才用于代码缩进,但当时显示器的分辨率是320*200,一行最多显示80个字符,这8个空格实在是太长了,于是就在编辑器中定义为4个空格,但后来有人觉得2个才好,还有人觉得1个更好,最后干脆作为编辑器配置项,根据喜好自定义吧。所以使用制表符缩进的代码在编辑器中的显示样式将会符合当前使用者的习惯,而使用空格缩进的代码将可能会导致当前使用者不适。多么细致的人文关怀,面向人性编程,面向开发者编程,时刻谨记。
战术思想七:调用必须有返回值
观察代码中的每一个方法,发现都有返回值,哪怕是返回固定值!
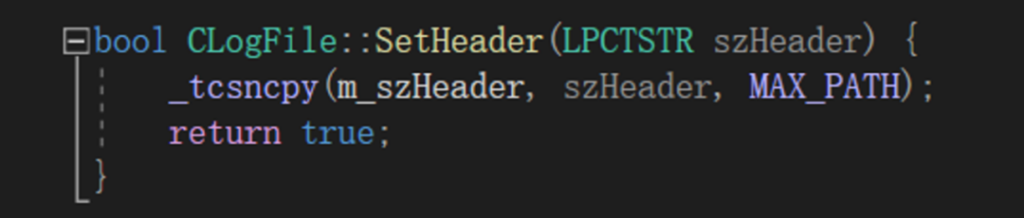
第七个战术级思想浮出水面:调用必须有返回值。绝大多数编程语言都允许调用没有返回值,但这帮顶级精英为什么在可以用这个规则的情况下还是不用呢?这就是接口的艺术,为了向下兼容,未雨绸缪,面向未来编程!因为谁也无法预测,随着代码的不断迭代,这个方法的使用条件可能会发生变化,而有返回值的调用是可以兼容没有返回值的调用的,这样可保持接口的历史一致性,进退自如。这样的设计一旦在public调用中发挥过一次作用,可就不是节约0.1秒的事了。
战术思想八:减少嵌套深度
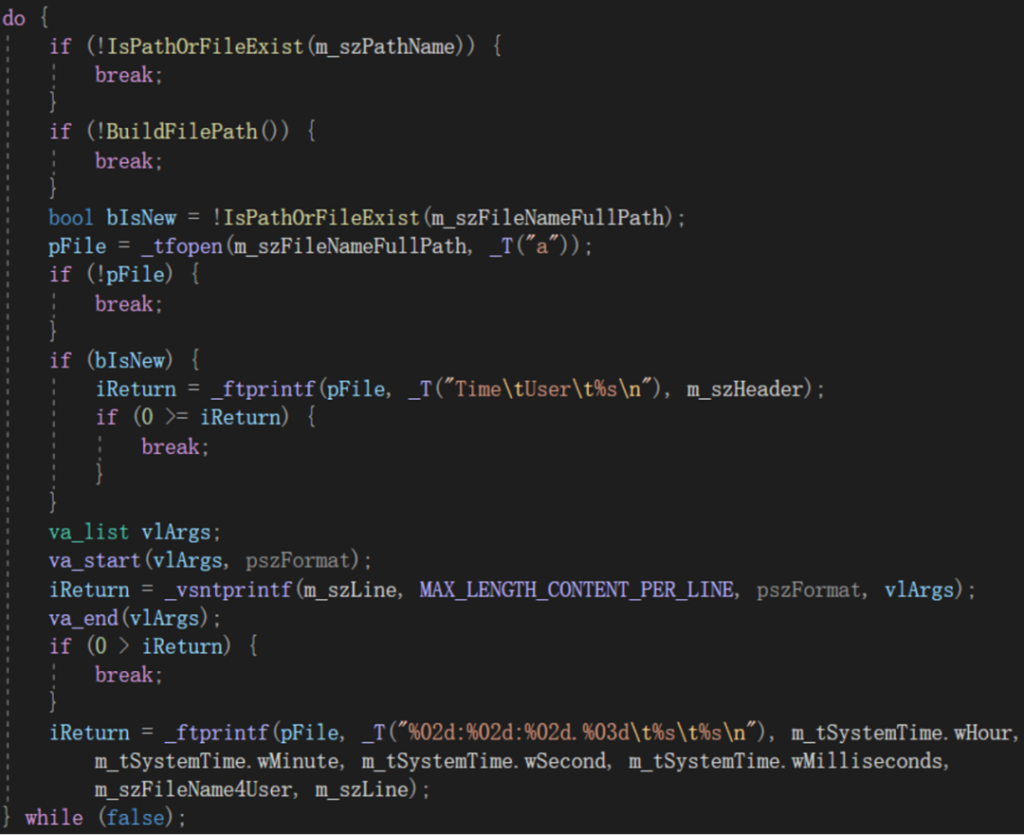
上面是Record方法中的一段代码,使用了一个do-while循环语句,但循环条件是个固定布尔值false,意味着这个循环永远只会执行一次,但为什么还要用循环语句呢?如果不用循环语句,正常的写法应该是这样的:
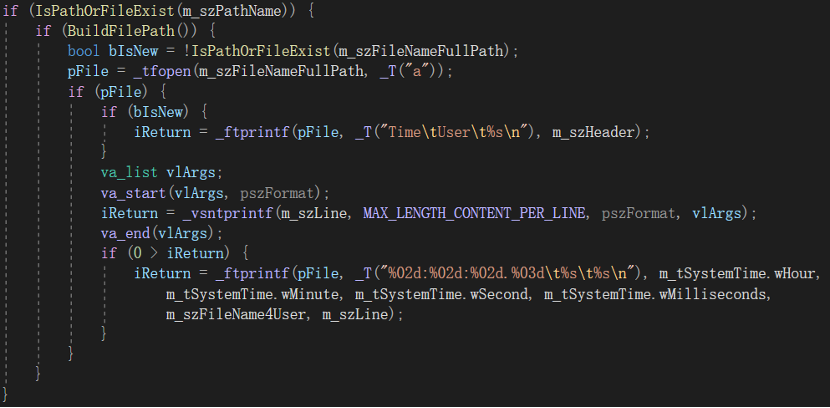
第八个战术级思想浮出水面:减少嵌套深度。嵌套深度决定了人类大脑的思考深度,而思考深度则决定了消耗的能量和思考的难度。所以嵌套深度较低的代码,让人思考起来会比较轻松且不易出错,而重度嵌套的代码则更容易让人疲倦且增加产生bug的几率。
战术思想九:辩证使用goto
这段代码使用do-while循环语句的结构,并配合break语句来减少逻辑嵌套。第九个战术级思想浮出水面:辩证使用goto。break语句的本质是goto语句,只是受限而已。而goto语句在早期面向过程编程的时代,由于其高效的操作效率而被滥用,把代码写的像面条一样,扯不清,理还乱,这导致了上世纪60年代的软件危机,并最终引发了软件工程革命。在面向对象编程的时代,业界统一的共识是禁止使用goto。但goto语句的操作效率确实很高,所以善用break这种阉割版goto可以起到鱼与熊掌兼得的效果。
战术思想十:同一函数代码不要跨屏
观察Record方法的代码行数达到36行,但业界一般的说法是每个函数的代码行数不要超过30行,理由是人类的脑容量问题。但0day的判断标准是,第十个战术级思想浮出水面:同一函数代码不要跨屏。只要任意函数的所有代码在当前流行屏幕尺寸大小下能够完全显示即可。理由是只要整个代码逻辑在人的静态目视范围之内,程序员的脑容量都够用。除了靠减少代码行数来防止纵向滚动屏幕,前面说的减少逻辑嵌套还能防止横向滚动屏幕。代码逻辑禁止跨屏规则能在很大程度上降低bug产生的几率。
再观察Record方法,发现一段有趣的代码:
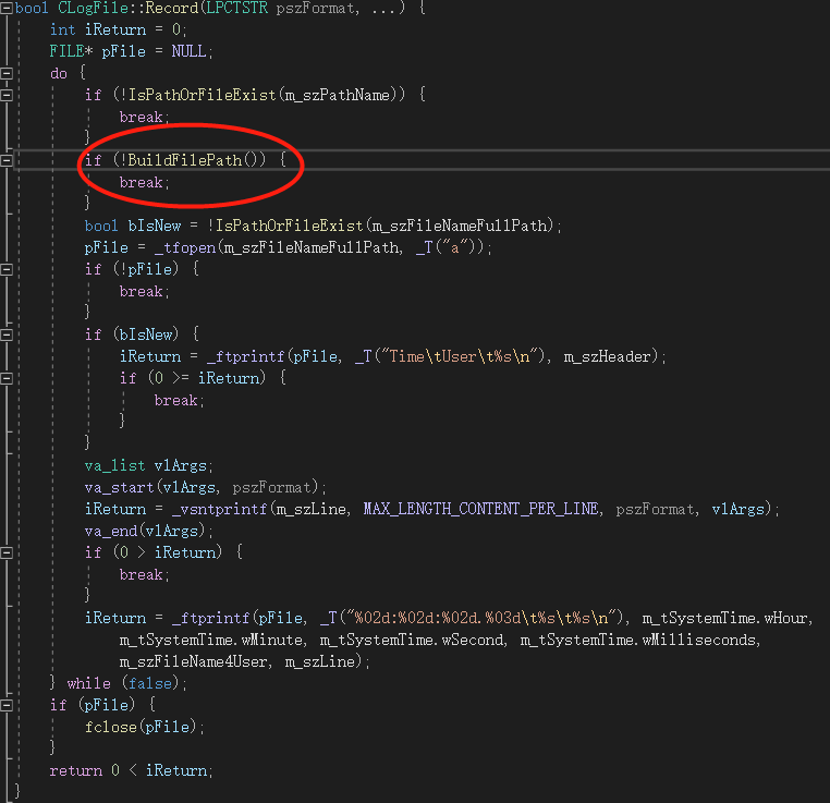
战术思想十一:尽量使用顺序代码结构代替判断代码结构
BuildFilePath方法用于构造日志文件名,其中使用了系统日期作为文件名的一部分,目的就是把日志文件按天分隔,以防止文件过大。这意味着每次写日志,都应判断是否该更换文件名,但这种更换每天只发生一次。而这段代码并没有根据日期是否更改而构造文件名,而是每次都按当前日期构造文件名,这意味着文件名在一天内的调用中都是重复构造相同的文件名,这不是做无用功吗?第十一个战术级思想浮出水面:尽量使用顺序代码结构代替判断代码结构。判断语句是bug产生的源泉,尽量不要使用,哪怕代码看上去有点愚蠢。不认同的人可以试试,使用判断语句来修改这段代码,让其看起来更有效率。当你被源源不断的bug改到怀疑人生时,你才能真切地体会到这个思想的精妙之处。对这个未知世界,心存敬畏,才能保你福如东海,寿比南山。
前面谈到了十一个战术思想,每一个战术思想,可能看过来都不复杂,但伟大往往都藏在细节中。十一个战术思想,处处都在体现着:以空间换时间,面向人性编程,面向开发者编程,面向未来编程,以及对这个未知世界心存敬畏。接下来我们谈谈战略级思想。
战略级思想
战略级思想一:赠人玫瑰,手有余香
再观察Record方法的定义,使用了非常罕见的不定长参数,第一个战略级思想横空出世:赠人玫瑰,手有余香。作为一个日志文件类的主要方法,通常就是把传入的字符串参数,存储到日志文件里就好了。为什么要使用一个非常冷门的技术?原因就是尊重传统,方便你的同行,让调用者更干、更爽、更安心。如果参数是一个字符串,则意味着调用方必须在调用此方法前,拼装好字符串:

使用不定长参数,则可以这样调用:

一行搞定!把方便留给别人,把困难留给自己,雷锋精神时刻谨记。面向人性编程,面向开发者编程,面向开源编程。
战略级思想二:简单通用
通览整体代码,系统调用只使用过一次Windows API,其余均使用C运行时库函数,第二个战略级思想横空出世:简单通用。作为一个工具类,会被广泛使用,包括跨平台应用。如果使用Windows API,此类要移植到Unix/Linux平台上将付出巨大代价。而C运行时库函数是语言标准而非平台标准,在功能表现上所有平台都是一致的,所以移植成本要低的多。而且代码中还使用了C运行时库函数的自适应字符集宏定义版本,使得此工具类无论编译目标应用是MBCS字符集还是Unicode字符集都无需修改一行代码!事实上,此工具类在组织内不但有多平台版本,甚至还有多语言版本,包括C#、java、VB等。受益于使用语言标准的设计思想,各语言、平台版本的代码一致性很高,产生bug的几率很小,移植成本非常低。
现在我们正式开始通过浏览代码来理解代码逻辑,先看类构造函数:
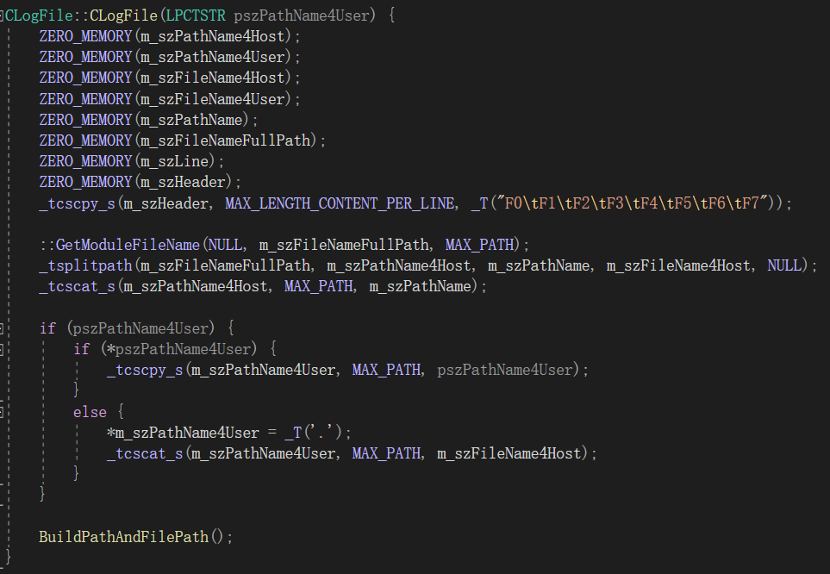
战略级思想三:默认值的艺术
这个初始化还是相当复杂的,对关键类成员变量的默认值进行了规划和设计,第三个战略级思想横空出世:默认值的艺术。为便于理解程序的设计思想,我写了一个测试程序,使用不同的参数调用构造方法,然后调用对应的成员变量获取方法,以查看成员变量的内容:
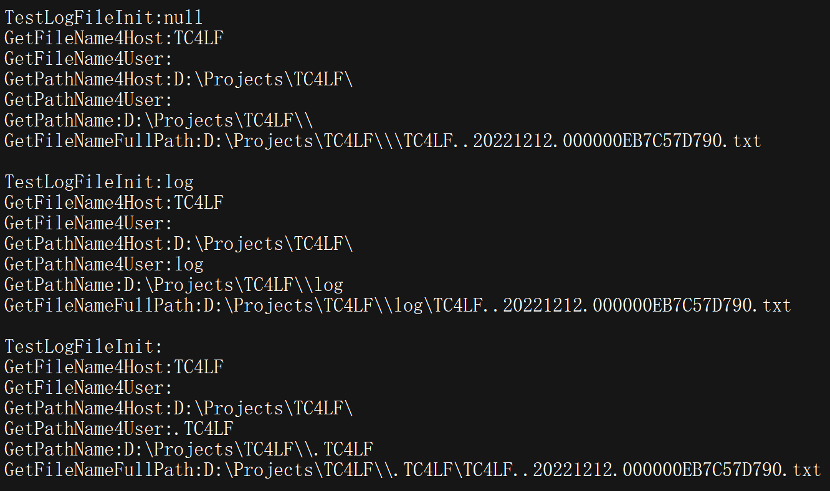
从以上结果可以看出,构造函数通过传递不同的参数,将成员变量初始化为不同使用理念的数据套。目的就是让调用者在构造完类后,即可使用Record方法开始记录日志,而无需任何配置!还是那句老话:把方便留给别人,把麻烦留给自己,雷锋精神时刻谨记。
三个战略级思想,以小搏大,已经从简单到人性上升到墨家的兼爱和利他主义,这其实就是面向开源的编程思想内核。下面我再谈三个核弹级思想。
核弹级思想
核弹级思想一:即时热调试
继续仔细研读测试结果,可了解代码初始化意图:给构造函数传参空指针(NULL),则日志文件路径自动配置为当前可执行文件路径,紧接着调用Record方法即可产生日志文件,nice!如果给构造函数传参非空字符串,如示例中是“log”,则自动配置日志文件路径为当前可执行文件路径后再附加“log”路径,enn…如果传参是空字符串或不传任何参数(这是默认情况,应该是该类建议的主要使用方式),则自动配置日志文件路径为当前可执行文件路径后再附加带前缀“.”的不包括扩展名的可执行文件名,what?
代码是看懂了,但为啥?难道要自动创建如此诡异的路径?但在Record方法中,不但没有找到创建路径的方法,还看到了这样一段代码:

这段代码的意思就是当日志文件路径不存在时,将退出Record功能,什么也不干!这个类的作用不就是记录日志吗?居然在某些情况下还不应记录?What the fuck!
第一颗核弹君临天下:即时热调试。像C/C++这种接近硬件底层的编译型语言,预定义有两种编译应用的形态:debug版本和release版本。debug版本用于在开发环境中调试,尤其是单步调试功能可以解决硬核的技术问题,而release版本用于正式发布,没有调试功能。但代码调试时,除了技术问题,还有更大量的业务逻辑问题需要调试。如果使用单步调试效率太低了,所以绝大多数C/C++程序员在debug版本中通过输出日志调试业务逻辑。这些日志通过宏定义控制只在debug版本中编译,而在release版本中忽略,因为正式发布的软件不能在用户方产生大量调试日志,否则日积月累会塞满用户的存储空间。但是,谁也不能保证在debug版本中能调试完所有的业务逻辑问题,如果在用户方部署的release版本出错,大家束手无策。在互联网发明以前,这个问题到也不太重要,因为即使在用户方发现程序错误,程序员也没办法到达现场解决问题。但现在的互联网技术可以支撑远程登录服务器或者个人计算机,赋予了技术支持人员可以在任何时间、任何地点、使用任何设备到达错误现场的能力,但老旧的编译时debug和release机制,在新时代下也没什么卵用。0day的精英们与时俱进,设计了这个动态debug和release机制:如果在当前可执行文件的目录下,存在一个特别指定的目录,则程序进入debug状态,并在那个目录下生成日志;否则程序保持release状态,不输出日志。牛B的思想闪耀星空!把代码的debug和release状态确认由编译时后移到运行时,这意味着当程序发生业务逻辑问题,程序员可直接登录到现场,程序都不用重启,直接建立指定目录,即可知道当前程序正在干什么,找到问题后,再把目录一删,挥一挥衣袖,不带走一片云彩!
这个顶级设计还有一些非常贴心的细节设计,第一是关于那个指定的目录。默认是不包括扩展名的当前可执行文件名,前面还有一个“.”。这是为了保持跨平台操作的一致性,因为Unix/Linux平台下的可执行文件没有扩展名,如果单纯使用当前可执行文件名,则因为重名而无法创建目录,所以前面加个“.”来保证不重名,还顺便成为隐藏目录,因为Unix/Linux的文件系统定义以“.”开头的目录或文件具备隐藏属性。虽然Windows平台下不存在这些问题,但0day的绝大多数精英都是Windows平台和Unix/Linux平台双料王牌,经常需要在多平台间切换工作,为保持操作一致性,只好委屈一下Windows平台了。但也无需焦虑,这个指定目录可以在初始化或运行时随便修改。修改指定目录还有一个使用技巧,比如在同一目录下有A1,A2,A3,B1,B2共5个应用程序,其中A1,A2,A3是有钩稽关系的第一组应用,B1,B2是有钩稽关系的第二组应用,可以设计为建立A目录,则在A目录中同时产生A1,A2,A3的日志,建立B目录,则在B目录中同时产生B1,B2的日志,达到相关应用群日志自动分组的目的。
第二是关于日志文件名。整个文件名分为5个部分:第一部分是应用程序名,这个很容易理解,一看就知道这个日志是哪个应用产生的;第二部分是一个自定义的名字,这个作用比较硬核,咱门后面再讲;第三部分是日志产生的日期,为了防止文件过大,每个应用程序每天只有一个日志文件;第四部分比较特殊,是运行时日志文件类实例的内存地址,what?这能干啥用?使用实例的内存地址意味着每次启动这个类,文件名就会发生变化,可用于指示这个应用程序在这个日期下的不同启动批次。第五部分是固定扩展名“txt”,指示系统可用文本编辑器打开此文件。整个设计考虑了使用上的方方面面,尽量让使用者更方便、更舒适,爱心妈妈,呵护全家。面向人性编程,面向开发者编程,面向开源编程。
核弹级思想二:统计日志
再看向文件写入内容的代码中使用制表符“\t”作为输出内容的分隔符,第二颗核弹石破天惊:统计日志。为了能理解这个设计,咱们先看看调用方是如何使用这个类的,典型调用像这样:

意图就是把需要输出的状态、数据,如调用的方法名、错误描述等,组织成类似表格字段的方式分隔输出。使用制表符可以保证用表格软件打开日志文件或把文本复制到表格软件里,效果是这样的:
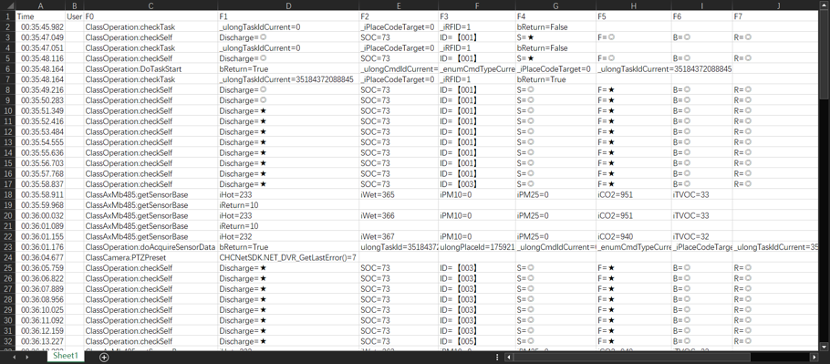
在第一个核弹的淫威下,再加上日志的记录时间精确到毫秒的加持,程序员们彻底放开了,写日志跟不要钱似的,疯狂输出,几乎每个函数在返回前都会把当前处理结果输出到日志里,面对这样的海量日志,用眼睛找bug会看瞎的。所以创造性的利用表格的相关排序、分类汇总、透视图等统计功能,快准狠地定位查找目标。比如示例那个日志,用透视图看是这样的:
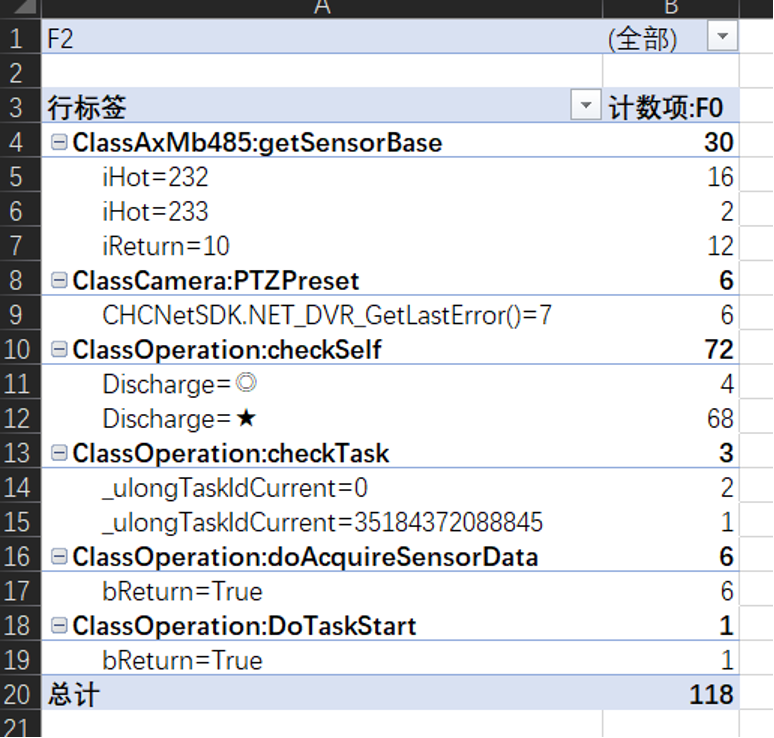
或者是这样的:
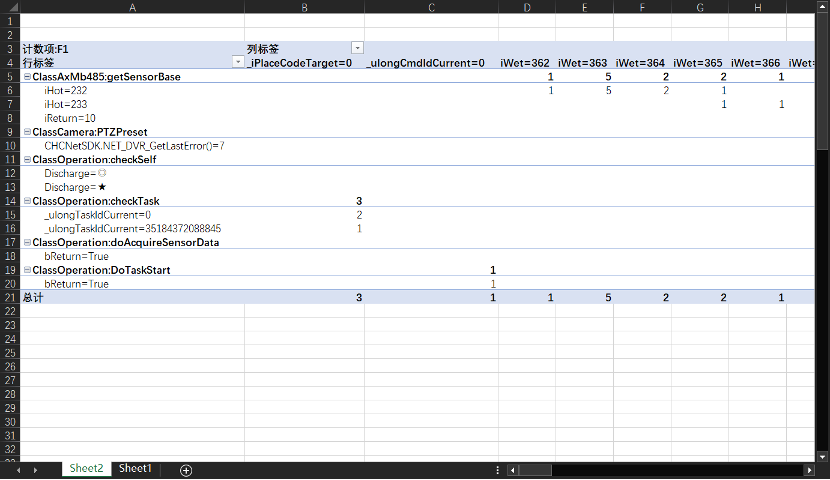
就说你想查啥?咋样都行,就是拖拖拽拽的事。bug往哪里躲?它太难了…羽扇纶巾,谈笑间,强撸灰飞烟灭。
核弹级思想三:调试多线程
还记得前面讲到文件名的第二部分吗?就是代码里的成员变量m_szFileName4User,它是干什么用的?看遍代码的上上下下,也看不出个所以然。我们对其赋值“robot”,看看出现啥情况:

日志文件名第二部分变成“robot”,日志文件中user列里面填充“robot”,仍然一头雾水!第三颗潜射核弹韬迹隐智:调试多线程。多线程调试是程序员的噩梦,因为人类的大脑无法精确模拟计算机多线程的运行过程。所以多线程程序所产生的bug,尤其是无法必现的bug,常常让人束手无策。在前面两颗核弹的加持下,给解决这个问题带来了希望。如果在日志文件类中加入同步机制,多个线程共享同一个日志文件类实例,则会导致多线程程序在调试状态下被强制串行化为单线程程序,由于运行环境的变化很可能触发不了那个多线程bug,所以每个线程必须单独使用各自的日志文件。在分析时,将相关的所有线程日志全部拷贝到一个表格文件中,利用排序功能就能知道每个时刻,各个线程都正在干什么。这个user列就是用于区分这条记录来自于哪个线程。多线程调试就这么被轻松地搞定了!说了那么多伟大,我都厌倦了:“老婆,快出来看上帝。”
核弹级思想是高手隐藏在编程中的不容易直接悟出来的彩蛋。但你一旦悟出来,一定会有醍醐灌顶的畅快淋漓。
写在最后
我已把这段代码上传到gitee,访问地址https://gitee.com/aeye/CTools/,欢迎大家共建,也可应用于项目中,给大家在代码的江湖中探险时提供一把趁手的兵器。
最后,希望同学们也能够创造出有思想,有灵魂,举手投足之间都透露出优雅的代码:
