玩嗨 OpenHarmony:基于 OpenHarmony 的自闭症早期筛查声纹特征滤波识别系统
原文引自:51CTO 开源基础软件社区 #DAYU200体验官 《DAYU200运行自闭症早期筛查声纹特征滤波识别系统》

1. 项目背景
根据《孤独症教育康复行业发展状况报告》,在全世界范围内每 54 个儿童就有一个儿童患有自闭症谱系障碍,目前中国的自闭症谱系障碍患者已经超过了 1300万,并且这个数量以每年近20万的速度增长。

我们通过调研发现我国关于自闭症谱系障碍方面的确诊缺乏统一的诊断标准,各大医院与医疗机构的主流诊断方案还是依托于量表等工具,误诊率高。但目前在确诊方面缺乏科学精准的检测仪器,导致被确诊为自闭症的患者平均年龄为4到5岁,远远滞后于18到24个月的最佳早期筛查诊断时机,使得患儿错过最佳康复治疗期。
我们团队基于以上痛点,以儿童说话声音作为原始数据,利用深度学习训练出的高精度模型对比分析自闭症谱系障碍儿童和正常儿童在声学特征上的差异,使用音频分析技术提取声学特征参数进行分析,基于润和大禹DAYU200从声学角度指导医生对待测儿童进行早期筛查,可将自闭症患者实际筛查确诊年龄提前至1到2岁,让自闭症谱系障碍儿童能极早地得到确诊,从而能够尽早进行干预治疗,最大限度地减少天生发育障碍对患者及整个家庭的影响。
2. 我们是谁?
守望星光团队于2021年6月在郑州轻工业大学梅科尔工作室成立,是一家专注于自闭症谱系障碍诊断技术研发的在校创新创业团队。梅科尔工作室的老师和同学们还必须在极为有限的条件下让价值最大化,工作室在老龄化、老年人康复、特殊人群关爱方向的漫漫征途。从拿着一封封介绍信去医院联系合作,一点点走访患者开始。如今,梅科尔工作室总计参与到60余个医疗项目的联合创新开发中,其中40多个是特殊人群关爱类项目。在脑卒中、自闭症和帕金森等领域完成了超过2000人次的病患数据样本收集,沉淀出300多个可用医疗案例。

3. 设计思路
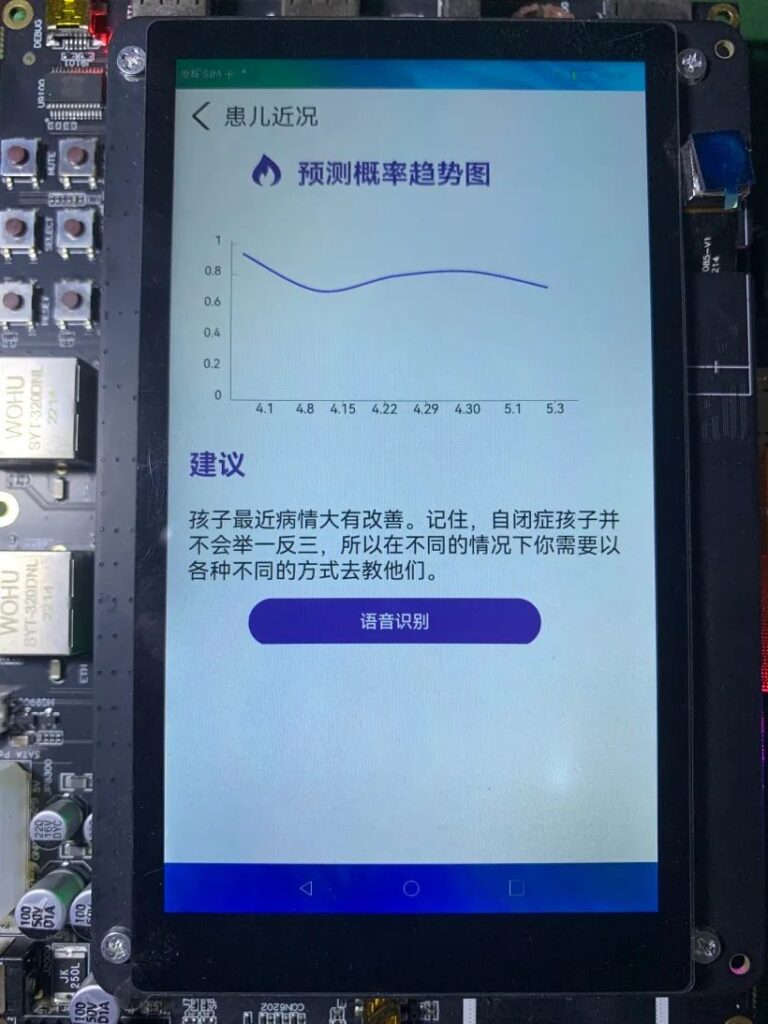
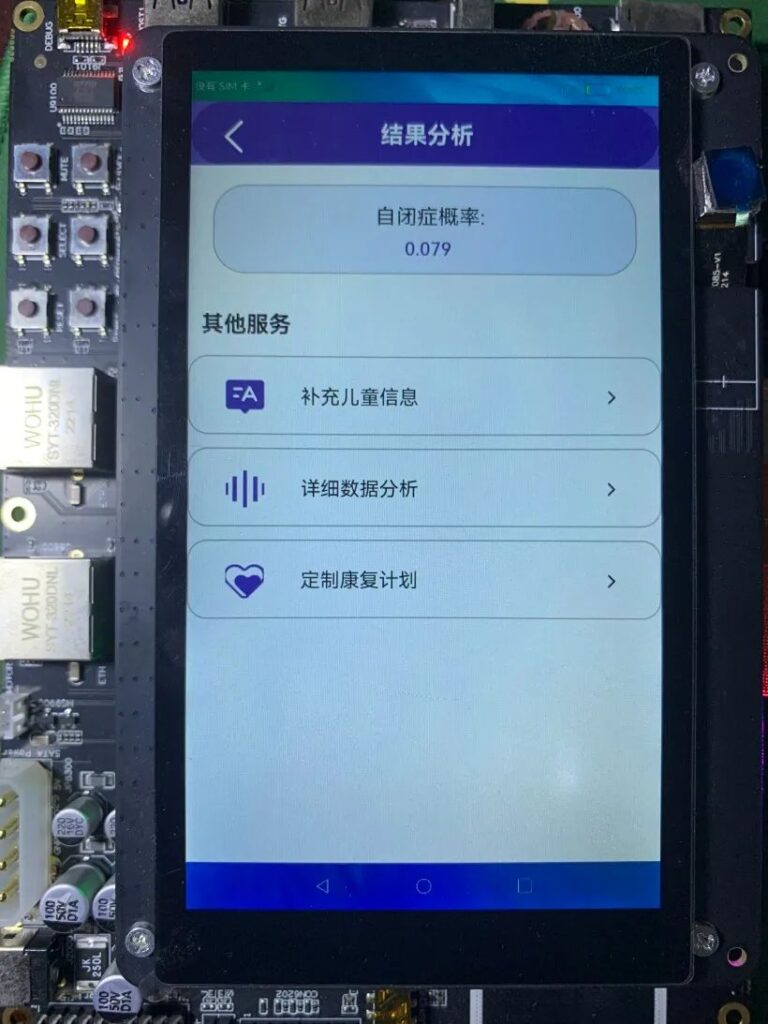
本项目通过神经网络和音频分析技术提取自闭症谱系障碍儿童的声学特征参数进行分析,筛选出最具有代表性的声学特征和分类识别性能最优的模型,从声学角度辅助医生对自闭症谱系障碍儿童进行早期诊断,并设计机器学习模型进行分类。构建模型,最终网络的准确性达到 93.8%。医生可在DAYU200端、网页Web端、桌面exe程序端、手机端鸿蒙APP查看结果,预测出自闭症谱系障碍准确率超过 70%,推荐可能患有自闭症谱系障碍孩子接受干预训练,避免错过最佳干预期。
3.1 开发技术设计框架
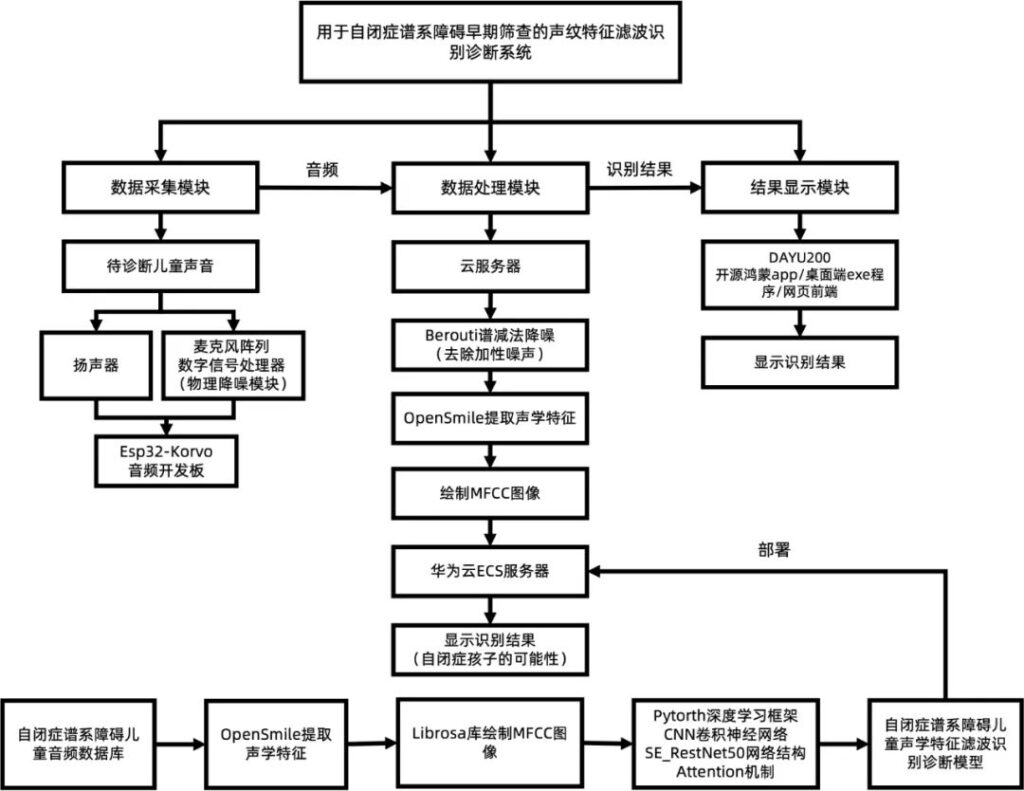
3.2 音频数据采集
项目的音频数据采集模块主要由三部分组成,分别是扬声器、三麦克风阵列数字信号处理器和Esp32-Korvo音频开发板。并通过回声消除算法、语音增强算法、降噪算法和音频自动增益算法收集音频数据,以此来保证受测者的音频数据质量。并通过蓝牙或WLAN传输音频数据至云服务器进行下一步处理。在内部布局上,通过精确测量开发板、扬声器、可充电电池的尺寸,合理规划设计了内部零件的位置,精准建模预留内部空间。效果图如下:

3.3 音频数据预处理
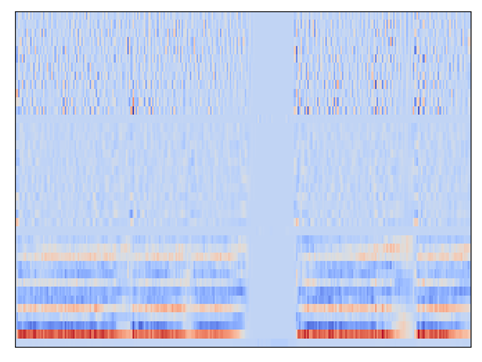
我们将数据采集模块得到的音频数据上传至我们的华为云服务器上,利用利用我们自主开发的降噪算法对收集到的声音进行二次降噪,除去高斯噪声、白噪声等等的一 些噪音,然后利用 OpenSmile 提取声学特征,得到的处理过后的数据会进行 Librosa 库绘制MFCC 图像。
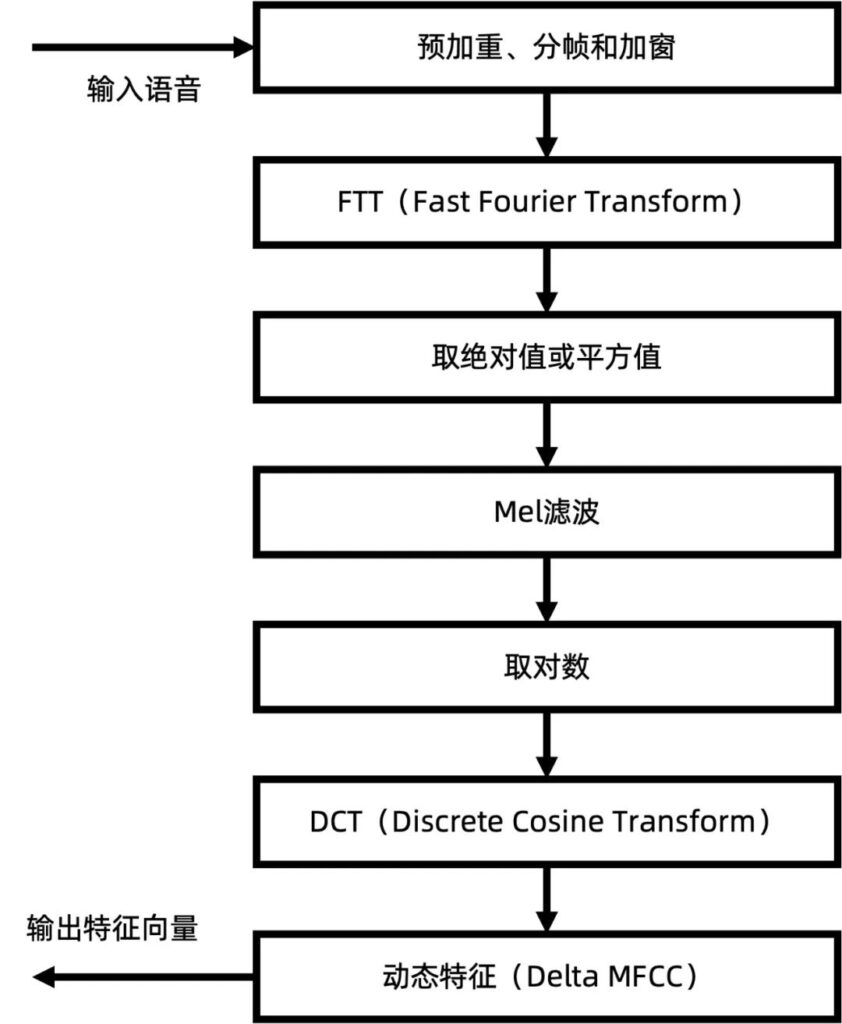
首先在音频转图像之前,通过 Berouti 谱减法对采样的自闭症患者语音中自带的加性噪声(背景噪声)得到噪声的频谱信息,并将其从频率空间中减去。同时为了避免提取困难,采用预加重技术将预加重滤波器加在原始音频上,强化高频部分,再通过分帧加窗使分析对象的信号变化不会突然消失。接着将连续的模拟信号转化为数字信号,通过快速傅里叶变化对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。并对语音信号的频谱取模平方得到语音信号的功率谱。接着利用三角带通滤波器对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。因此一段语音的音调或音高,是不会呈现在梅尔倒谱系数内。换言之,以梅尔倒谱系数为特征的声学特征滤波识别诊断系统,并不会受到输入语音的音调不同而有所影响。此外,还可以降低运算量。
最后,经离散余弦变换(DCT)得到 MFCC 系数。
音频转图像具体流程展示图如下:
提取声学特征并绘制出的 MFCC 图像如下:
3.4 图像数据分析
在深度学习模型预测程序中预测待测者自闭症谱系障碍的患病概率,采用CNN卷积神经网络来进行图像识别,包含4个卷积层和3个全连接层,每个卷积层后面有一个LeakyRelu (激活函数)增强非线性,每两个卷积层分别紧跟一个最大值池化层缩小特征图组成一个卷积组模块,卷积层的输出通道数按顺序分别是64, 32, 128, 64,卷积层的输出特征图进入全连接层前平铺成向量,然后进入三个线性变换层逐层降低向量的维度,每个线性变换紧跟一个Dropout层防止过拟合,线性变换的输出长度分别是128, 64, 1,最后输出的一维向量用于二分类,输出自闭症谱系障碍儿童的概率和正常儿童的概率。基于深度神经网络的算法,通过计算机较强的学习能力来学习自闭症患者与正常人的声学特征,以此达到对自闭症患者语音数据的有效识别。
4. 方案效果





5. 开发环境
- DevEco Studio for OpenHarmony3.0.0.900
- OpenHarmony版本:3.1_Release
- 开发板:DAYU200

写在最后
我们最近正带着大家玩嗨OpenHarmony。如果你有好玩的东东,欢迎投稿,让我们一起嗨起来!有点子,有想法,有Demo,立刻联系我们:
合作邮箱:zzliang@atomsource.org