开源鸿蒙内核源码分析系列 | 页表管理 | 映射关系保存在哪里(转载)

什么是页表?
页表,其作用是记录虚拟地址和物理地址的映射关系的。它也需要内存空间存放内容,便于查询。本篇说说页表的使用流程和实现过程。
开源鸿蒙有三种虚拟空间(LosVmSpace):
- 内核空间(g_kVmSpace):数量一个,内核也是程序,需要有容身之所,需要通过外部工具先烧录至flash指定位置,再启动加载至内存固定位置开始运行,存放内核数据代码的这部分空间称之为内核空间,其包括中断向量表(vectors),代码区(.text),只读数据区(.rodata),可读写数据区(.data),未初始化的全局变量(.bbs)和页表区。
- 内核分配空间(g_vMallocSpace): 数量一个,内核启动后,运行期间需要不断的申请和释放内存,这些内存从哪里来呢 ? 由内核分配空间提供,注意此处是动态以内存池的方式分配没错,但不能简单的理解为堆空间,因为内核态栈空间(stack),堆空间(heap),映射区(map)都是由它提供,它们没有明显的地址边界,你无法只从地址判断运行逻辑。
- 用户空间 :数量多个,是应用程序运行的空间,在这个空间中 栈区,堆区,映射区 ,代码区,数据区 会有明显的边界,栈区在高地址位,向下生长,堆区在低地址位,向上生长,数据区在更低的地址位,代码区在更更低的地址位。
页表是记录这三种虚拟空间地址映射关系的 ,而内核空间与内核分配空间的虚拟地址不会重叠所以可设计成共用一张页表,存储在内核空间中,而所有用户空间的虚拟地址范围是一致的,必须独立记录映射关系,统一存储在内核空间的页表区,当用户进程切换时便提供这份页表给MMU,MMU将对这份页表增删改查。所谓的 缺页中断 就是在这份页表中没有查到虚拟地址映射的物理地址,处理缺页中断是将内容调入物理内存并更新页表的过程。再比如打开某个文件 背后需要做 文件映射 ,为这个文件单独开辟一个线性区,将文件内容以页为单位加载到物理内存页帧中,由页表保存线性区地址和物理地址的映射关系。

Alexander the Great visits the studio of Apelles by Willem van Haecht
内核页表 | g_firstPageTable
此处会涉及到编译器的知识,__attribute__这个关键词是GNU编译器中的编译属性,__attribute__((section(“section_name”))),含义是将作用的函数或数据放入指定名为section_name对应的段中。再说的简单点是编译器帮我们在数据区的指定的位置开了一个全局变量名叫section_name 代码见于 los_arch_mmu.c:
#define MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS 0x4000U //16K
__attribute__((aligned(MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS))) \
__attribute__((section(".bss.prebss.translation_table"))) UINT8 \
g_firstPageTable[MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS];
#ifdef LOSCFG_KERNEL_SMP
__attribute__((aligned(MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS))) \
__attribute__((section(".bss.prebss.translation_table"))) UINT8 \
g_tempPageTable[MMU_DESCRIPTOR_L1_SMALL_ENTRY_NUMBERS];
UINT8 *g_mmuJumpPageTable = g_tempPageTable;
#else
extern CHAR __mmu_ttlb_begin; /* defined in .ld script | 内核临时页表在系统使能mmu到使用虚拟地址运行这段期间使用,其虚拟地址保存在g_mmuJumpPageTable这个指针中*/
UINT8 *g_mmuJumpPageTable = (UINT8 *)&__mmu_ttlb_begin; /* temp page table, this is only used when system power up | 临时页表,用于系统启动阶段*/
#endifUINT8分配了16K 等于分配了4个物理页,一个物理页的单元大小是按8位算的4K。能存储2^10 = 1024个UINT32数据,虚拟地址的长度为UINT32。
为什么要这么做呢 ? 切换进程就需要提供页表的位置,用户进程的页表是在内核创建用户进程的时候就提供好了,就已经知道了具体位置,那内核的页表呢 ? 它同样也需要在内核运行之前就提供好具体位置,注意,此处说的是页面的位置,而非页表内容。我们写的普通代码使用的全局变量并不能设定其在数据区的具体地址,你是做不到让程序指定一个变量的地址必须是地址(0x2345)对不对 ? 所以只能由编译器来指定内核页表的具体地址。
抛个问题,从代码中知道内核还有一个临时页表g_tempPageTable,为何要有临时内核页表呢 ?
用户页表
/// 创建用户进程空间
LosVmSpace *OsCreateUserVmSpace(VOID)
{
BOOL retVal = FALSE;
LosVmSpace *space = LOS_MemAlloc(m_aucSysMem0, sizeof(LosVmSpace));//在内核空间申请用户进程空间
if (space == NULL) {
return NULL;
}
//此处为何直接申请物理页帧存放用户进程的页表,大概是因为所有页表都被存放在内核空间(g_kVmSpace)而非内核分配空间(g_vMallocSpace)
VADDR_T *ttb = LOS_PhysPagesAllocContiguous(1);//分配一个物理页用于存放虚实映射关系表, 即:L1表
if (ttb == NULL) {//若连页表都没有,剩下的也别玩了.
(VOID)LOS_MemFree(m_aucSysMem0, space);
return NULL;
}
(VOID)memset_s(ttb, PAGE_SIZE, 0, PAGE_SIZE);//4K空间置0
retVal = OsUserVmSpaceInit(space, ttb);//初始化用户空间,mmu
LosVmPage *vmPage = OsVmVaddrToPage(ttb);//找到所在物理页框
if ((retVal == FALSE) || (vmPage == NULL)) {
(VOID)LOS_MemFree(m_aucSysMem0, space);
LOS_PhysPagesFreeContiguous(ttb, 1);
return NULL;
}
LOS_ListAdd(&space->archMmu.ptList, &(vmPage->node));//页表链表,先挂上L1,后续还会挂上 N个L2表
return space;
}用户空间的页表由内核空间提供,因为页表大小和物理页框对应,默认都是4K,所以直接申请物理页,页表的作用是存储虚拟地址和物理地址映射关系的,但它自身也是需要映射的,又该如何记录这种关系呢 ? 鸿蒙使用了一个很巧妙的办法 偏移法 。KERNEL_ASPACE_BASE为内核空间的起始地址,SYS_MEM_BASE为物理内存的起始地址。
#define KERNEL_VADDR_BASE 0x40000000
#define KERNEL_VMM_BASE U32_C(KERNEL_VADDR_BASE) ///< 速度快,使用cache
#define KERNEL_ASPACE_BASE KERNEL_VMM_BASE ///< 内核空间基地址
#define SYS_MEM_BASE DDR_MEM_ADDR ///< 物理内存基地址
///分配连续的物理页
VOID *LOS_PhysPagesAllocContiguous(size_t nPages)
{
LosVmPage *page = NULL;
if (nPages == 0) {
return NULL;
}
//鸿蒙 nPages 不能大于 2^8 次方,即256个页,1M内存,仅限于内核态,用户态不限制分配大小.
page = OsVmPhysPagesGet(nPages);//通过伙伴算法获取物理上连续的页
if (page == NULL) {
return NULL;
}
return OsVmPageToVaddr(page);//通过物理页找虚拟地址
}
VOID *OsVmPageToVaddr(LosVmPage *page)//
{
VADDR_T vaddr;
vaddr = KERNEL_ASPACE_BASE + page->physAddr - SYS_MEM_BASE;//page->physAddr - SYS_MEM_BASE 得到物理地址的偏移量
//因在整个虚拟内存中内核空间和用户空间是通过地址隔离的,如此很巧妙的就把该物理页映射到了内核空间
//内核空间的vmPage是不会被置换的,因为是常驻内存,内核空间初始化mmu时就映射好了L1表
return (VOID *)(UINTPTR)vaddr;
}vaddr = KERNEL_ASPACE_BASE + page->physAddr – SYS_MEM_BASE; 表示申请的物理地址在物理空间的偏移量等于映射的虚拟地址在内核空间的偏移量,不需要存储映射关系,这简直就是神来之笔,拍案叫绝。但也由此可知 每个进程的页表(L1,L2)在逻辑地址层面不在一起,因为物理地址是不可能在一起的。
MMU页表
MMU地址映射是连续的物理地址映射到连续的虚拟地址,切成一定的块大小映射。开源鸿蒙内核MMU一级条目分成:段(1MB) 、 页两种。
#define MMU_DESCRIPTOR_L1_TYPE_PAGE_TABLE (0x1 << 0) ///< 一级条目类型按页分
#define MMU_DESCRIPTOR_L1_TYPE_SECTION (0x2 << 0) ///< 一级条目类型按段分二级条目分成 大页(64KB) , 小页(4KB) , 极小页(1KB) 三种:
#define MMU_DESCRIPTOR_L2_TYPE_LARGE_PAGE (0x1 << 0) ///< 二级条目类型按大页分
#define MMU_DESCRIPTOR_L2_TYPE_SMALL_PAGE (0x2 << 0) ///< 二级条目类型按小页分
#define MMU_DESCRIPTOR_L2_TYPE_SMALL_PAGE_XN (0x3 << 0) ///< 二级条目类型按极小页分
下图绘制了 小页(4KB) 获取物理地址内容的全过程 ,将步骤和数据放在一块理解:
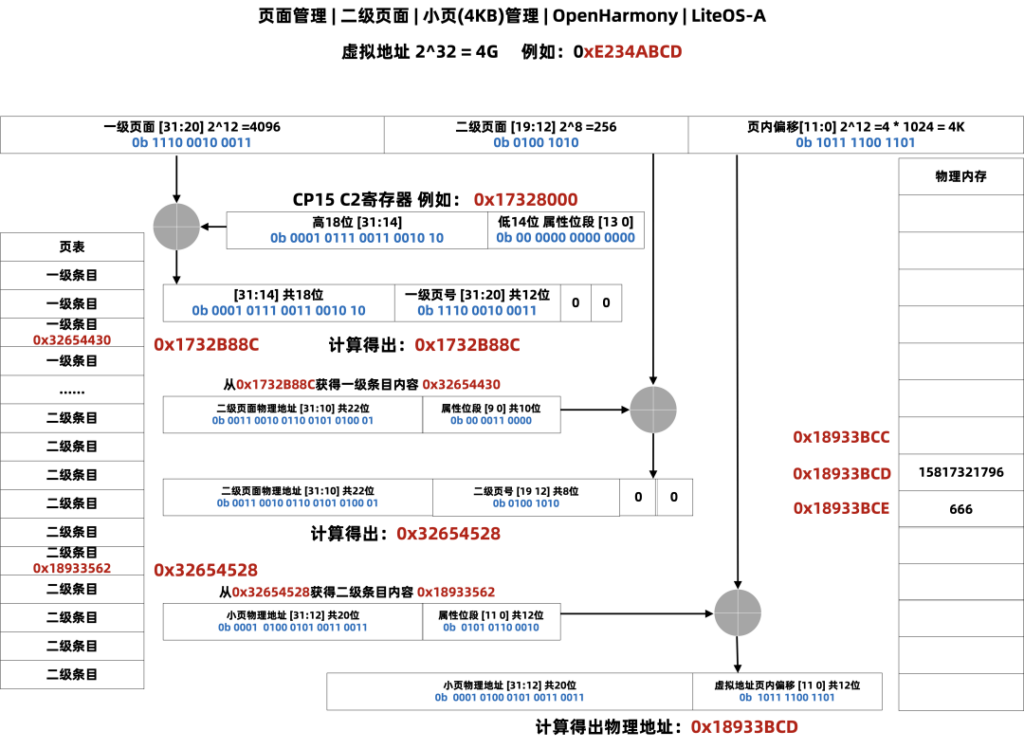
过程解读:
- 第一步:CPU 提供虚拟地址 0xE234ABCD。
- 第二步:计算L1地址,从 CP15的C2寄存器取出高18位用于高位,将虚拟地址高12用于中位,低二位补0, 得出L1地址:0x1732B88C。
- 第三步:从L1地址:0x1732B88C 中取出内容L1内容:0x34564430 用于计算L2地址。
- 第四步:计算L2地址,从 0x34564430 取出高22位用于高位,将虚拟地址中8用于中位,低二位补0, 得出L2地址:0x32654528。
- 第五步:从L2地址:0x32654528 中取出内容 L2内容:0x18933562 用于计算物理地址。
- 第六步:计算物理地址,从 0x32654528 取出高20位用于高位,将虚拟地址低12用于低位, 得出最后的物理地址:0x18933BCD。
- 第七步:从物理地址 0x18933BCD 获取数据内容 15817321796 即虚拟地址0xE234ABCD获取的最终数据。
百文说内核 | 抓住主脉络
子曰:“诗三百,一言以蔽之,曰‘思无邪’。”——《论语》:为政篇。
百文相当于摸出内核的肌肉和器官系统,让人开始丰满有立体感,因是直接从注释源码起步,在开源鸿蒙内核源码加注释过程中,每每有心得处就整理,慢慢形成了以下文章。内容立足源码,常以生活场景打比方尽可能多的将内核知识点置入某种场景,具有画面感,容易理解记忆。说别人能听得懂的话很重要! 百篇博客绝不是百度教条式的在说一堆诘屈聱牙的概念,那没什么意思。更希望让内核变得栩栩如生,倍感亲切.确实有难度,自不量力,但已经出发,回头已是不可能的了。
百万汉字注解内核目的是要看清楚其毛细血管,细胞结构,等于在拿放大镜看内核。内核并不神秘,带着问题去源码中找答案是很容易上瘾的,你会发现很多文章对一些问题的解读是错误的,或者说不深刻难以自圆其说,你会慢慢形成自己新的解读,而新的解读又会碰到新的问题,如此层层递进,滚滚向前,拿着放大镜根本不愿意放手。
与代码有bug需不断debug一样,文章和注解内容会存在不少错漏之处,请多包涵,但会反复修正,持续更新,v**.xx 代表文章序号和修改的次数,精雕细琢,言简意赅,力求打造精品内容。百篇博客系列思维导图结构如下:

根据上图的思维导图,我们未来将要和大家一一分享以上大部分关键技术点的博客文章。
百万汉字注解.精读内核源码
如果大家觉得看文章不过瘾,想直接撸代码的话,可以去下面四大码仓围观同步注释内核源码:
gitee仓:
https://gitee.com/weharmony/kernel_liteos_a_note
github仓 :
https://github.com/kuangyufei/kernel_liteos_a_note
codechina仓:
https://codechina.csdn.net/kuangyufei/kernel_liteos_a_note
coding仓:
https://weharmony.coding.net/public/harmony/kernel_liteos_a_note/git/files
写在最后
我们最近正带着大家玩嗨OpenHarmony。如果你有用OpenHarmony开发的好玩的东东,或者有对OpenHarmony的深度技术剖析,想通过我们平台让更多的小伙伴知道和分享的,欢迎投稿,让我们一起嗨起来!有点子,有想法,有Demo,立刻联系我们:
合作邮箱:zzliang@atomsource.org